
.jpg)
.jpg)
Упрощение рабочих алгоритмов мониторинга производительности и сетевой безопасности. Часть 1
После того, как сети были вывернуты наизнанку неожиданным увеличением удаленной работы, организации стали более уязвимы к успешному проникновению. Когда мы сталкиваемся с потенциально серьезной угрозой, очевидно, что нам нужно предпринять наименьшее количество шагов и потратить на это как можно меньше времени, чтобы эффективно и быстро перейти от обнаружения к реагированию. Каким бы очевидным это ни казалось, многие на собственном опыте узнают, что существующие инструменты и процессы не всегда соответствуют этому желанию.
Почему? Во многих случаях речь идет просто о необходимости собирать большие объемы необработанных данных, не имея соответствующей возможности извлекать выжимки, которые могли бы быть преобразованы в ответы.
Подход, который зачастую используется, заключается в том, чтобы обобщить эти большие объемы необработанных данных в некие усредненные метаданные. Конечно, бывают ситуации, когда это весьма полезно, но бывают и такие, когда буквально каждый бит информации необходим для того, чтобы воссоздать событие или понять его последствия. Итак, что же нам остается? Как нам вывести на поверхность полезную информацию, не отбрасывая критически важные детали, которые могут понадобиться для расследования?
Давайте рассмотрим пример той роли, которую может сыграть правильный рабочий процесс в решении этой задачи.
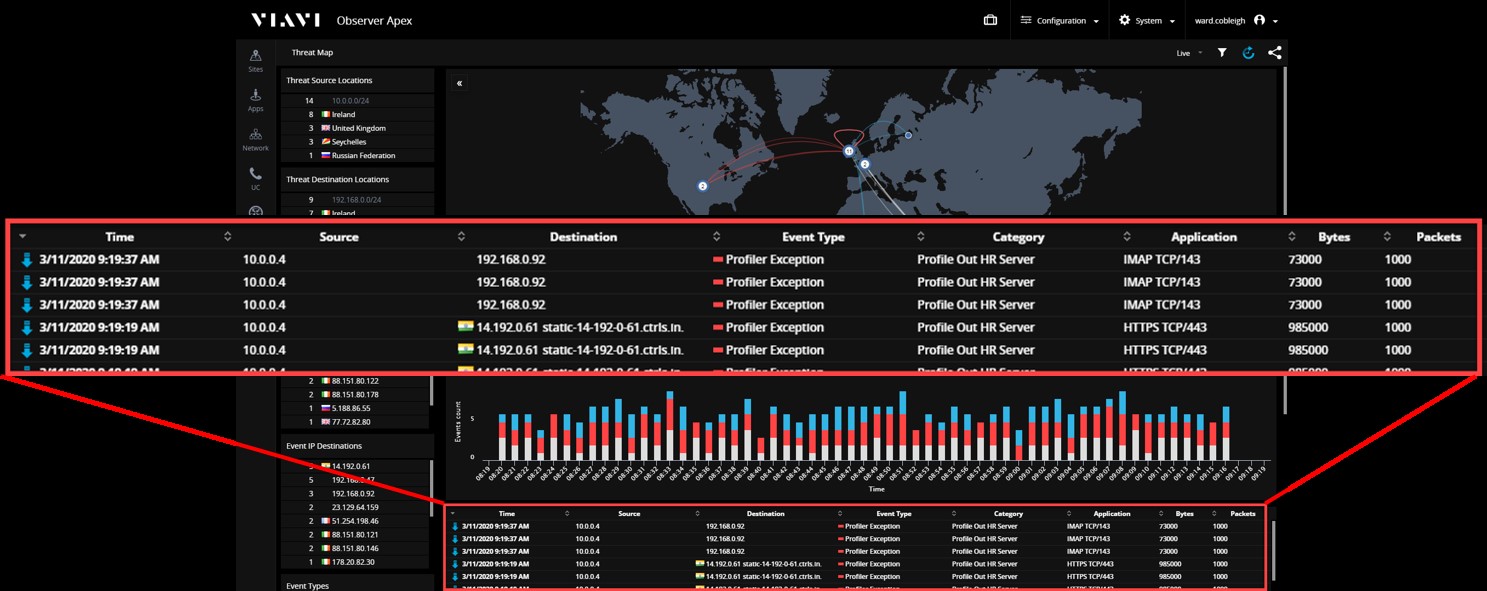
Шаг 1: Обнаружение аномальной активности
Знание того, как должны вести себя наши хосты или устройства, должно позволить нам быстро понять, когда они ведут себя не так. В этом примере из карты угроз верхнего уровня мы видим, что у нас есть HR сервер, который внезапно начал участвовать в сессиях, не входящие в его стандартный профиль поведения.
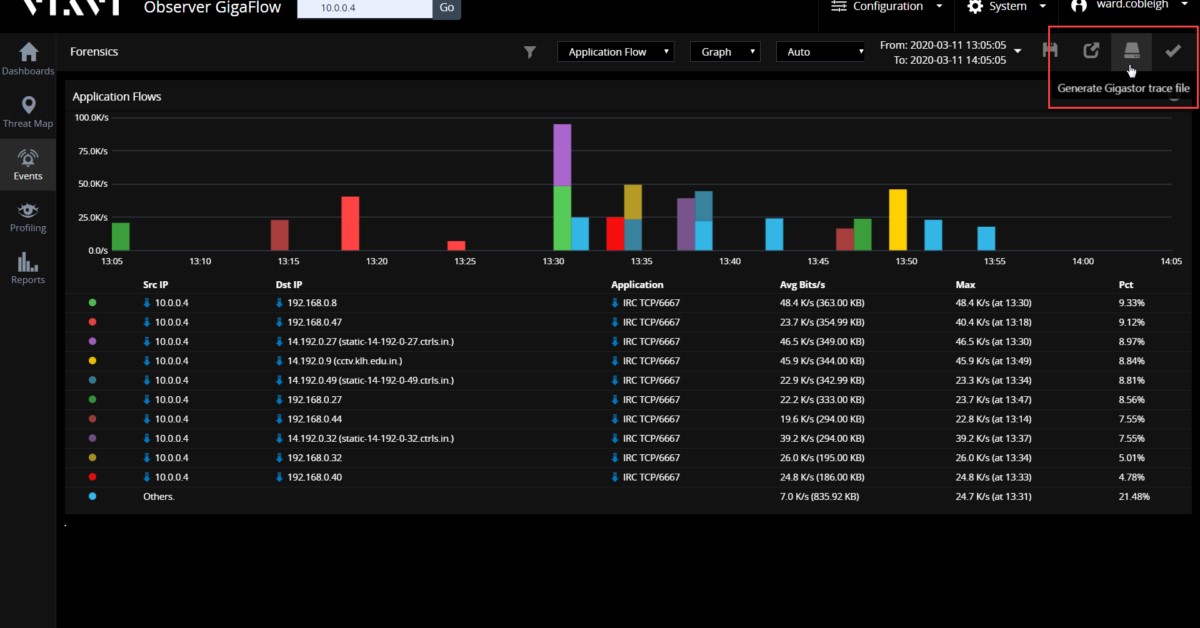
Шаг 2: Фокусировка
Наше внимание быстро переключается на этот один хост - какие связи у этого сервера являются нетипичными? Глядя на события, описывающие исключения из ожидаемого поведения, мы видим, как часто происходят неожиданные сессии, и более подробно о том, с кем наше устройство коммуницирует и какие типы сессий происходят.
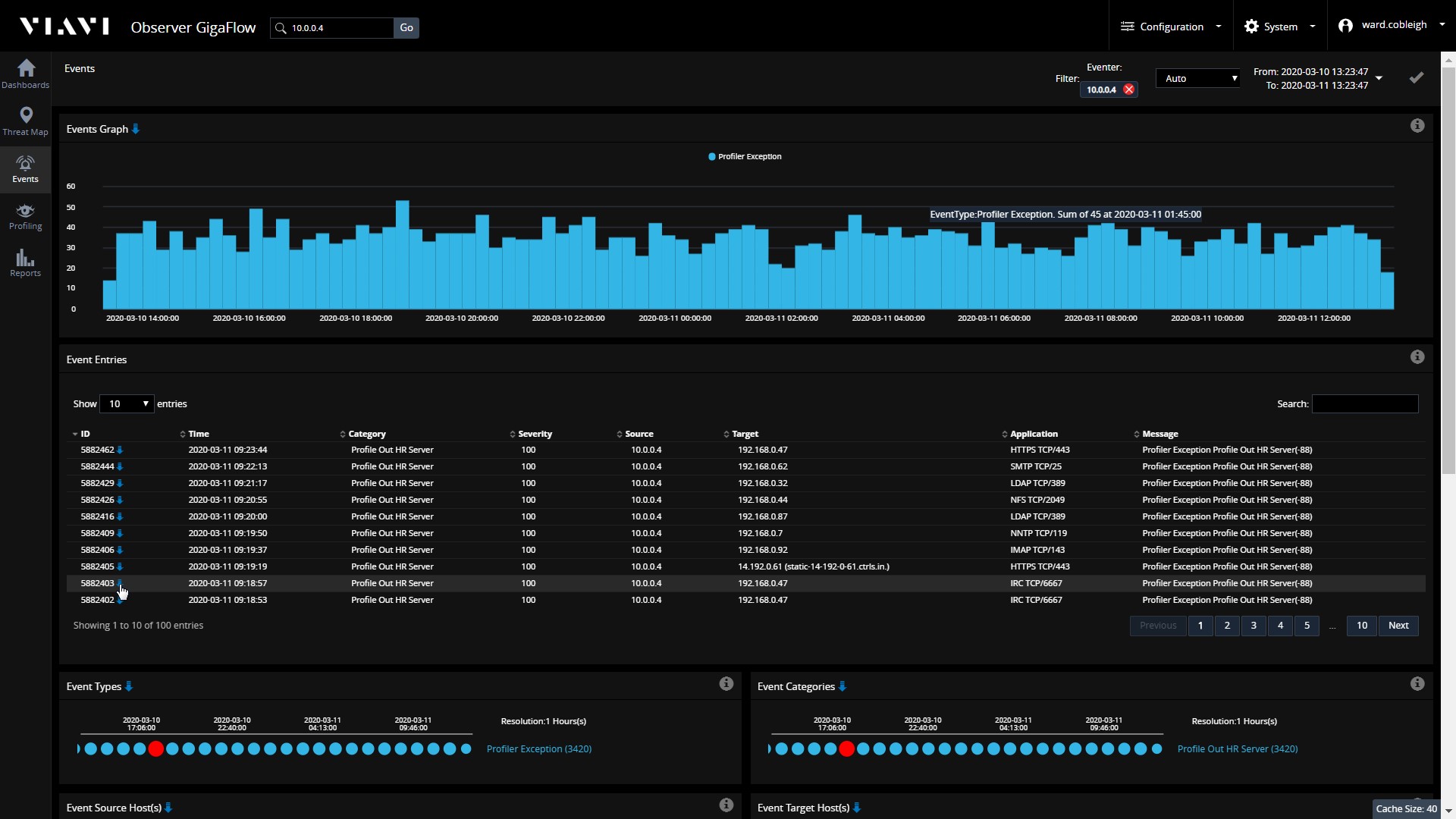
В данном примере, допустим, особый интерес вызывает один конкретный пункт - трафик на TCP-порте 6667. С чем взаимодействует наш HR сервер и что именно туда было передано?
Шаг 3: Расследование
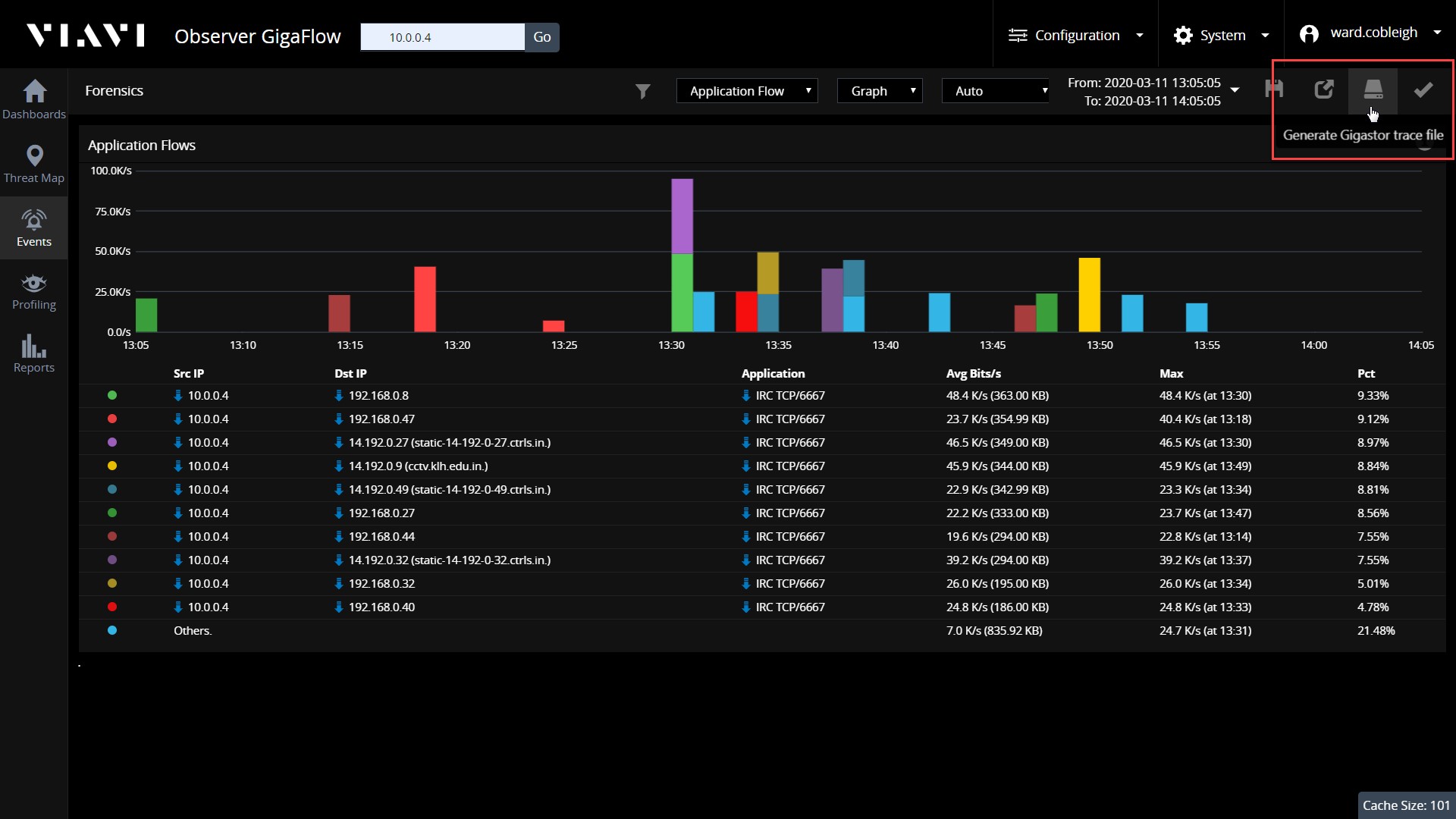
Наш анализ подробно описывает каждую отдельную сессию, которая произошла на сервере с использованием этого порта, период времени, в течение которого эти сессии происходили, и объем данных, которые были переданы. Опция экспорта дает нам возможность извлекать пакеты, которые обеспечивают каждый бит информации, переданный по кабелю. Если произошла утечка данных, у нас будут доказательства, необходимые для того, чтобы точно задокументировать то, что было скомпрометировано.
Выводы
Что мы проиллюстрировали в этом примере:
- Важность автоматической идентификации, извлечения и представления действенной информации - наш HR-сервер связывается с тем, с кем обычно не должен, мы должны выяснить, что происходит.
- Ценность сочетания этой действенной информации с простым, эффективным рабочим процессом - мы перешли от детектирования к анализу в три этапа.
- Простота использования - практически любой член нашей команды мог увидеть и понять проблему и буквально перейти от карты к пакетам. Теперь аналитик по безопасности или владелец устройства/сервиса имеет четкое описание проблемы и «сырые» данные, необходимые для ее решения.
- Значение синергии совместного использования данных NetFlow (NetFlow, IPFIX, и т.д.) и пакетных данных.
Читать далее >> Часть 2
Появились вопросы или нужна консультация? Обращайтесь!

Вечный параноик, Антон Кочуков.
См. также:








Авторизуйтесь для этого