
.jpg)
.jpg)
Какие параметры и как измеряются при анализе производительности сервисов и приложений?

Не важно, каким решением вы пользуетесь для анализа производительности своих сервисов, коммерческим или умным админом с анализатором протоколов WireShark, важно понимать фундаментальные основы ключевых метрик, на что они влияют и как их можно измерить в реальности.
Это самый популярный вопрос от многоуважаемых заказчиков в проектах: «Какие параметры и как вы можете измерить?». Для особо экономных ИТ-директоров откроем секрет, что это можно сделать вручную, считая дельты между пакетами в буфере захвата анализатора протоколов WireShark, понимая работу протокола и умело пользуясь фильтрами (пример). Единственным ограничивающим фактором здесь будет время, которое уйдет на выявление и устранение проблемы.
Итак, большинство корпоративных приложения в качестве транспорта используют протокол TCP, который ориентирован на установление соединения и его надежном поддержании с контролем доставки пакетов. Поэтому анализируя дельты по времени между определенными пакетами (см. диаграмму ниже) можно собрать все основные метрики:
- CT (Connection Time) – время установления соединения с сервером. Этот параметр наглядно отражает задержки в сети, так как пакеты в этот момент передаются малой длины и с приоритетом, настроенным для данного приложения. Пакеты при установлении соединения обрабатываются сервером/клиентом также с высоким приоритетом. Некоторые системы мониторинга на этой стадии дают развернутую оценку, и делят время CT на составляющие: RTT и SRT и CD (Client Delay). Это позволяет оценить по времени SRT, занят ли сервер и на сколько в момент установления соединения.
- TTFB (Time To the First Byte) – время до отправления первого байта. Не все системы его измеряют, но некоторые пользователи находят в нем интерес. На наш взгляд, оно включает много составляющих и больше вносит сумятицы.
- DTT (Data Transfer Time) – время необходимое для передачи всех данных от клиента или сервера на его запрос. Высокие значения данного параметра надо анализировать совместно с оценкой объема запроса, так как если значение высокое, то это обычно перегружено приложение. Чем? Или количеством запросов или их объемом. Также необходимо при анализе смотреть на наличие ошибок на TCP уровне – Windows Zero Size, TCP Reset и т.д. Так как эти TCP флаги существенно влияют на скорость передачи данных.
- RTT (Round Trip Time) – круговое время передачи по сети. По сути, дельта между отправкой пакета со стороны клиента или сервера и получением подтверждения на этот пакет (ACK). В зависимости от точки захвата реального трафика может отражать время передачи к клиенту или к серверу. Чаще это дельта по времени между пакетом, который содержит данные на запрос и первым подтверждением его получения (ACK). Главный параметр для оценки сетевой составляющей ИТ-инфраструктуры, так как это чистое время передачи по сети плюс небольшая составляющая на уровне погрешности, – это Client Delay.
- SRT (Server Response Time) – время необходимое серверу на подготовку первого пакета с данными в ответ на запрос клиента. Основной параметр, который показывает задержку сервера и далее необходимо анализировать, чем занят сервер, используя и другие решения, например, на основе SMNP или SCOM.
- RR (Retransmission rates) – наиболее наглядный индикатор, который показывает потери пакетов в каналах связи или очередях активного оборудования. Многие специалисты при анализе потери пакетов исключают факт проверки настроек активного оборудования, а на нем может быть отключена фрагментация пакетов, некорректно настроен MTU, время жизни и т.д.
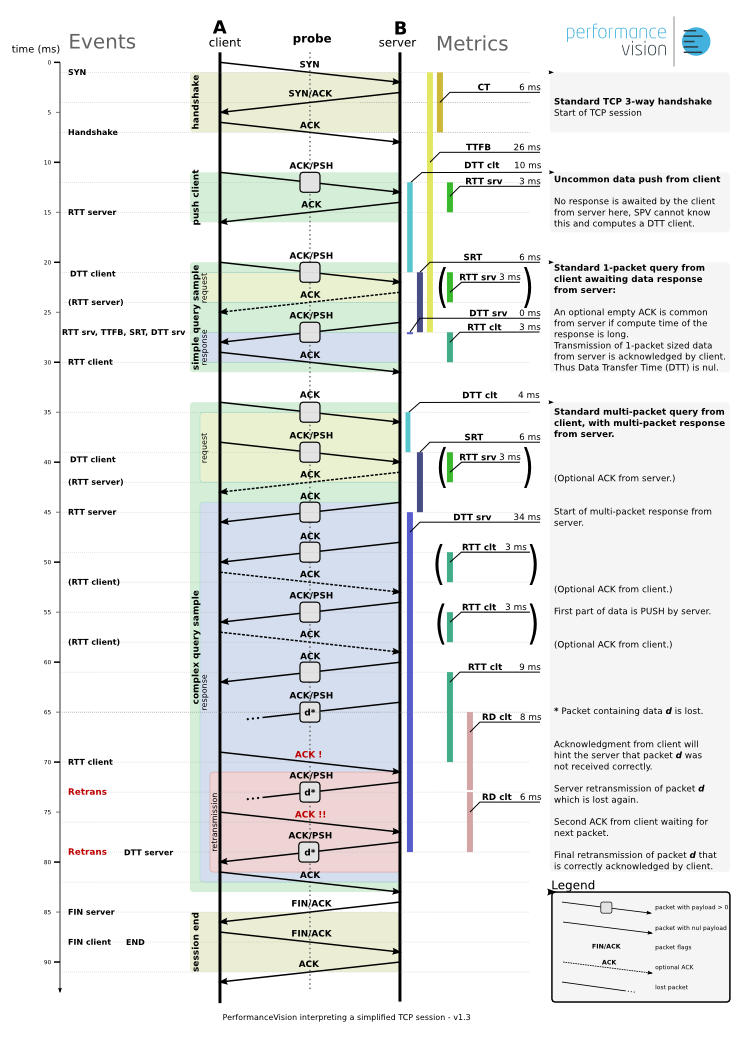
Время отклика сервиса для клиента, это сумма всех составляющих и как видно на диаграмме составляет 90 мс. И наша задача при анализе производительности найти слабое звено и устранить его.
В рамках данного материала мы рассмотрели основные показатели, по которым можно судить о производительности сервиса и отдельных его элементов. А уж как вы это будете делать, так сказать ваше дело – на выбор есть и WireShark и коммерческие решения из квадрата Gartner.
Всегда на связи, Игорь Панов
См. также:
- Какие параметры влияют на производительность приложений? Часть 1. TCP Window Size
- Диагностика сети и приложений с помощью OptiView XG
- Как правильно подключиться к сети для захвата трафика? Часть 1. Захват трафика на стороне клиента или сервера





Авторизуйтесь для этого