
.jpg)
.jpg)
Часть 1. Пять ключевых функций систем мониторинга производительности сети!
Решения для мониторинга и диагностики производительности сети получили активное развитие по мере ускорения сетей передачи данных и появления новых сложных корпоративных приложений и сервисов. Каковы же основные возможности и особенности, которыми эти решения обладают сейчас? Представляем вашему вниманию пять наиболее значимых функциональных возможностей для управления современными, высокоскоростными, многоуровневыми сервисами и сетями.
Давным-давно сетевые инженеры, обслуживающие сети масштаба предприятия, должны были просто обеспечивать доступ к сети и достаточную пропускную способность соединения для связи с различными серверами, а также корректной работы приложений и конечных устройств. С точки зрения сетевой модели OSI, основной акцент их работы был направлен на уровни 1-4. Верхние слои модели OSI в большей или меньшей степени игнорировались, так как потоки данных и весь траффик передавались по сети через общие полосы пропускания и очереди ресурсов.
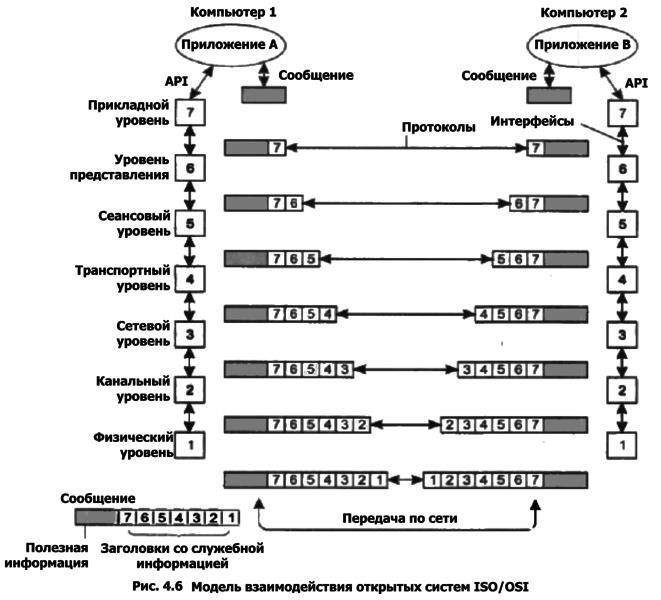
Время шло, и сетевое оборудование становилось все сложнее, позволив по-разному, вплоть до конкретной точки сети, идентифицировать и обрабатывать различные потоки данных. Для этих целей использовались различные модели качества обслуживания (quality of service, QoS) и методы формирования трафика (traffic shaping) в зависимости от приоритетов приложений. Кроме того, все возрастающая зависимость от критически важных для бизнеса приложений заставила сетевых инженеров разбираться с верхними уровнями сетевой модели OSI, чтобы они могли быть в состоянии помочь идентифицировать любые инциденты или проблемы, связанные с сетью, серверной операционной системой, программным обеспечением для виртуализации и самими приложениями. Но для того, чтобы это сделать, необходим инструментарий, чтобы иметь возможность идентифицировать подобные проблемы и корректно их устранить.
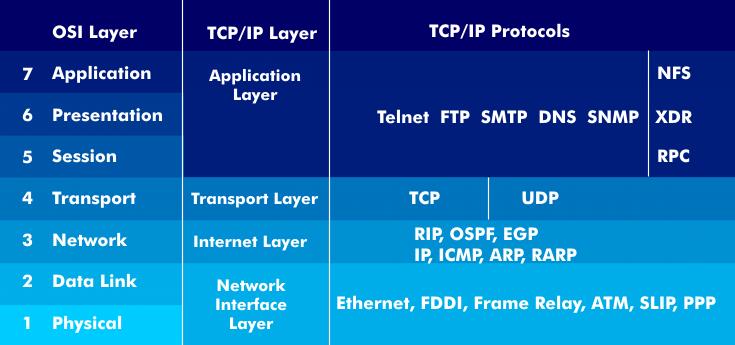
В большинстве своем решения для мониторинга и диагностики производительности сети развились из более традиционного и менее сложного программного обеспечения для мониторинга сети. Эти инструменты мониторинга для получения информации о «здоровье» сети обычно используют утилиту Ping, работающую на базе сообщений протокола ICMP (Internet Control Message Protocol, протокол межсетевых управляющих сообщений), входящего в стек протоколов TCP/IP, а также возможности по обеспечению синхронизации и проведению опросов из центра мониторинга (комбинация polling/traps) на основе протокола SNMP (Simple Network Management Protocol, простой протокол сетевого управления). Более современные реализации включают в себя возможности мониторинга, а также визуального представления базового и интеллектуального анализа состояния всей сети вплоть до самих приложений. Большинство современных инструментов для мониторинга производительности сети позволяют выполнять пять следующих функциональных возможностей:
- мониторинг сети и приложений;
- обнаружение проблем с виртуализацией и операционными системами;
- анализ сетевых проблем;
- анализ захваченных данных приложений и потоков;
- поиск корневой причины инцидента или проблемы.
В зависимости от поставщика решения для мониторинга производительности сети, эти задачи могут выполняться с различной степенью детализации. И чем этот инструмент точнее, тем более сложными могут оказаться задачи по его внедрению и управлению. Таким образом, очень важно понять, в чем именно нуждается ваша компания или организация и найти нужный компромисс между степенью детализации и сложностью искомого решения.
Для этого давайте начнем с более детального исследования пяти основных функциональных возможностей, которые сегодня наиболее часто можно встретить в современных инструментах для мониторинга производительности сети.
Мониторинг сети и приложений
Как уже мы упоминали ранее, современные инструменты для мониторинга и диагностики производительности сети эволюционировали от решений для мониторинга сети, которые использовали возможности протоколов ICMP и SNMP. Рутинный запрос ping от сервера мониторинга сети направлялся в различные сети, к серверам и другим устройствам, которые нужно было контролировать. Если контролируемое устройство переставало отвечать на запросы, инструмент мониторинга маркировал это устройство как «не работающее» (down) и предупреждал о событии персонал службы технической поддержки.
SNMP позволяет собирать различные типы данных от сетевых устройств и серверов, поддерживающих протокол. Для сетевых устройств это, обычно, означает мониторинг конкретных состояний интерфейса устройств и скорости передачи данных. С помощью этого протокола также можно следить за состоянием аппаратных средств, включая блоки питания, вентиляторы, использование памяти и т. д.
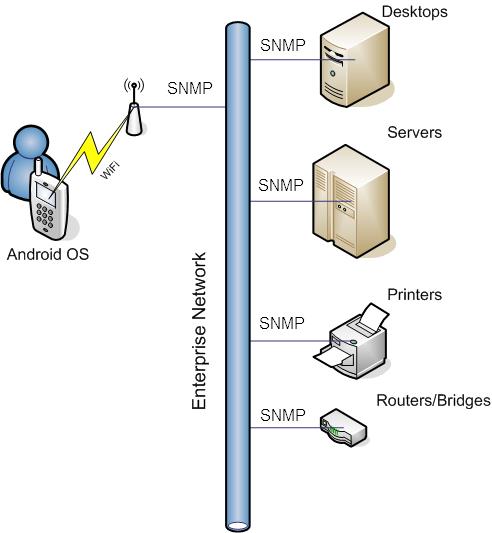
Некоторые инструменты для мониторинга производительности сети также способны получать и отправлять различные сообщения Syslog (системного журнала). Протокол Syslog является общим стандартом для лог-сообщений (информации о различных событиях с привязкой ко времени) всех устройств сетевой инфраструктуры. Эти сообщения посылаются централизованному инструментарию мониторинга сети, который обеспечивает их хранение, проведение анализа, а также использует для уведомления инженеров из службы технической поддержки в случае нарушения нормальной работы системы.
Обнаружение проблем с виртуализацией и операционными системами
Нарушения также могут возникнуть — и возникают — между сетью и приложением. Они включают в себя проблемы на уровне виртуализации, операционной системы сервера и любого промежуточного программного обеспечения, влияющего на нормальное функционирование сетевой инфраструктуры.
Мониторинг гипервизоров (или мониторов виртуальных машин) для выявления проблем с производительностью, которые могут вызывать снижение скорости соединения на уровне приложения, может производиться индивидуально. То же верно для операционных систем хостов и промежуточного программного обеспечения, которые осуществляют управление коммуникациями через распределенные системы. Поставщики решений для мониторинга производительности сети используют различные методы для обнаружения и реакции на эти типы проблем, а также обеспечивают несколько большую поддержку для более широкого круга гипервизоров, операционных систем и промежуточного программного обеспечения, чем другие.
Анализ сетевых проблем
В дополнение к предоставлению простого статуса «работает / не работает» (up/down) и информации об использовании, продукты для мониторинга производительности сети могут выполнять более сложную и автоматизированную диагностику сети. Она включает в себя мониторинг протокола маршрутизации и вывод оповещений при возникновении незапланированных изменений протокола маршрутизации. Кроме того, некоторые из этих продуктов являются интеллектуальными, то есть включают в себя средства аналитики, которые позволяют понять, как работают различные WAN-технологии, виртуальные оверлеи и функции QoS. Также они могут быть настроены автоматически предупреждать при возникновении проблем и, даже, предпринимать автоматизированные действия по решению этих проблем.
Анализ захваченных данных приложений и потоков
Наиболее важные обязанности современных инструментов для мониторинга производительности сети сосредоточены вокруг анализа захваченных данных и потоков. Существует несколько разных методов для захвата пакета данных на различных участках сети для проведения автоматического и / или ручного анализа. Наиболее распространенными из них являются:
- развертывание агентов по сбору информации о передаваемых данных вдоль всех критических узлов сети;
- способность использовать функциональную возможность захвата пакетов, встроенную в аппаратное обеспечение некоторых маршрутизаторов / коммутаторов.
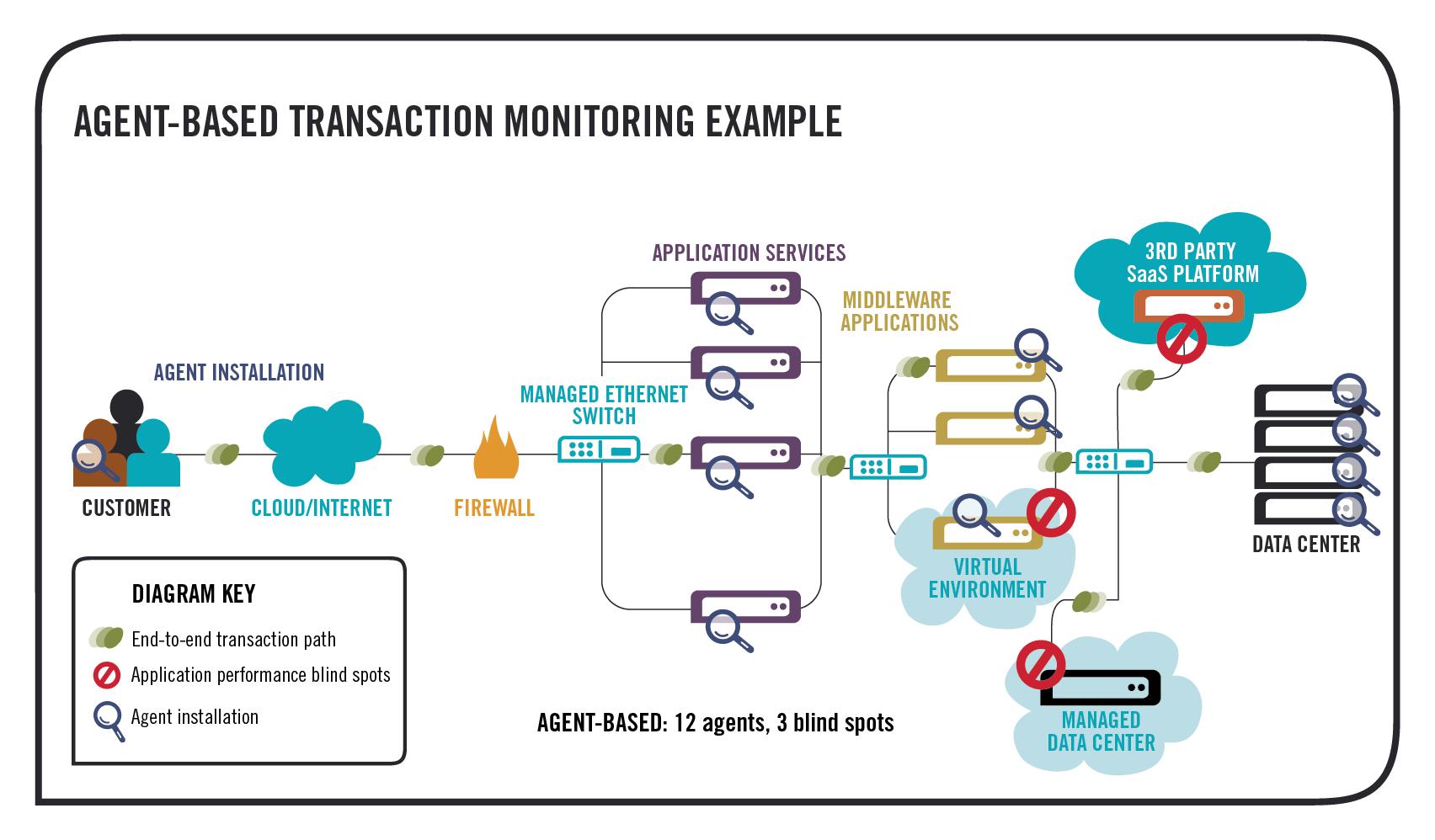
Способность исследовать пакеты для выполнения более глубокого анализа приложений является сейчас стремительно растущей потребностью во многих организациях корпоративного масштаба. Используя глубокую проверку пакетов, сетевые администраторы могут идентифицировать большинство коммуникационных проблем, связанных с приложениями, которые иначе с очень большой вероятностью остались бы незамеченными.
Коллекция сетевых потоков собирает статистику IP-сети в виде информации о приеме и передаче данных сетевыми интерфейсами. После того, как эти данные были экспортированы на центральный сервер и проанализированы с помощью специального инструментария для анализа потоков, встроенного в решения для мониторинга производительности сети, администраторы сети из службы технической поддержки могут идентифицировать источник траффика и приемник информации, а также получить детальную информацию о применении политик QoS при столкновении трафиков во время того, как поток данных передается по сети. В конечном итоге, эта информация может быть использована для идентификации любых проблем с конфигурацией или выявления перегруженных участков для различных сетевых путей между сетевыми устройствами.
Поиск корневой причины инцидента или проблемы
Возможность комбинировать различные события, собранные и проанализированные с помощью решения для мониторинга производительности сети, также может быть использована для автоматизированного аналитического поиска корневой причины инцидента или проблемы. Если произошедшая в сети проблема была инициирована событиями на нескольких компонентах этой сети, то многие решения для мониторинга производительности сети используют средства искусственного интеллекта для установления корреляционной зависимости событий и определения наиболее вероятной первопричины возникновения проблемы.
Это одна из наиболее трудоемких функций для настройки, так как она требует, чтобы все устройства и системы мониторинга были безупречно сконфигурированы. К примеру, если время устройств не синхронизировано с помощью протокола Network Time Protocol, реальное и зафиксированное время событий будет отличаться. Это может негативно сказаться на проводимом интеллектуальном анализе, приведя, в итоге, к неверному выводу о корневой причине инцидента или проблемы. Но если один раз установить и должным образом произвести настройку, то автоматизированный инструментарий по поиску первопричины проблемы поможет сэкономить огромное количество времени, которое иначе бы было потрачено на поиск и устранение неисправностей.
Всегда на связи, Игорь Панов
См. также:
- Часть 2. Какие проблемы способна решать система мониторинга сети?
- Часть 3. Как купить систему мониторинга производительности сети, идеальную для вашего случая?
- Часть 4. Сравнительный анализ ТОП-инструментов для мониторинга производительности сети
- Обзор решений Network Performance Monitoring (NPM). Руководство покупателя!





Авторизуйтесь для этого