
.jpg)
.jpg)
Упрощение рабочих алгоритмов мониторинга производительности и сетевой безопасности. Часть 2
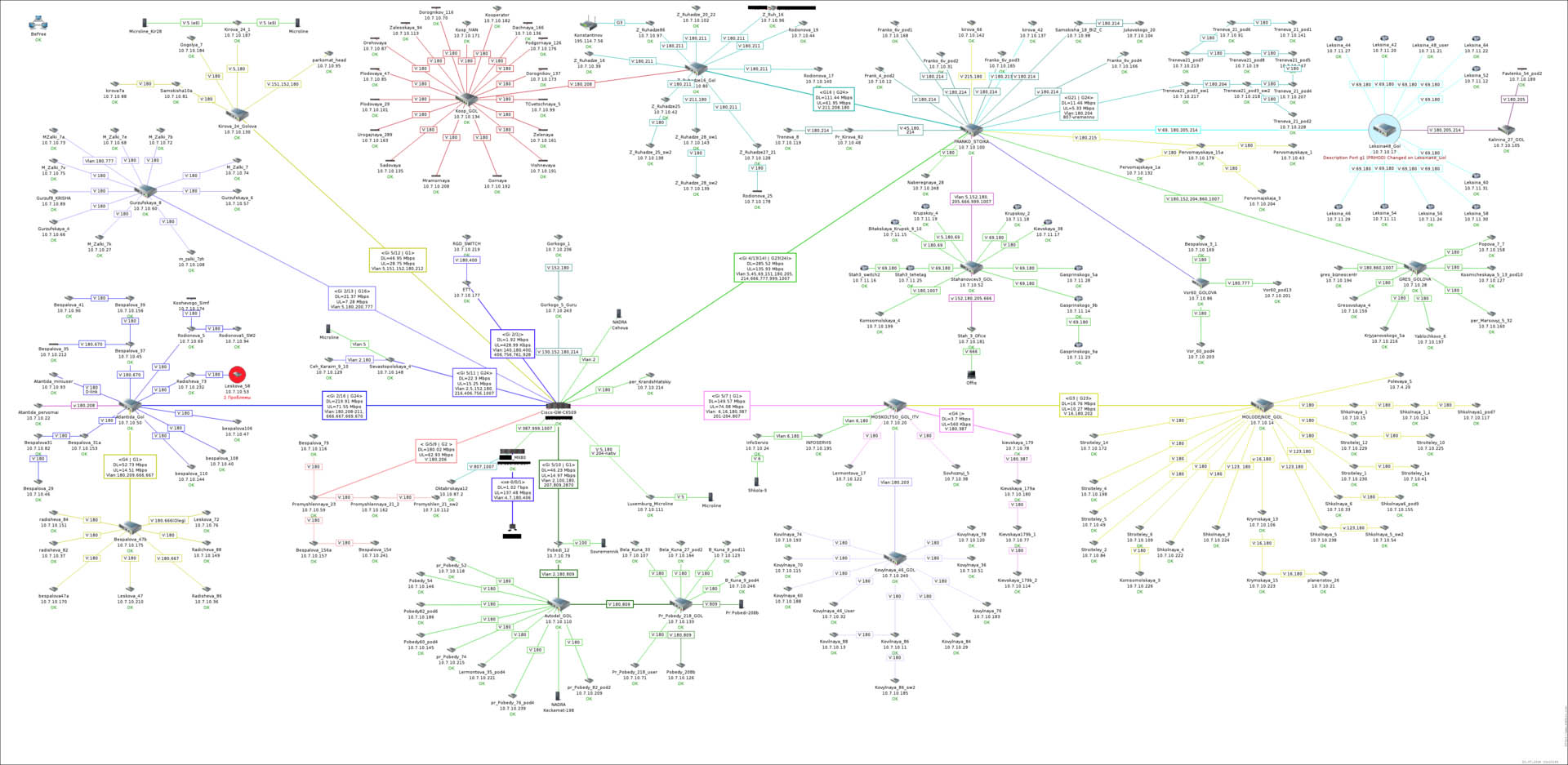
Пример структурной схемы сети
Начало статьи >> Часть 1
Для выявления и решения проблем производительности комплексных систем важно иметь полное представление о том, как работают все их компоненты.
Для этого большинство производителей NPMD решений (мониторинг сети и сервисов) предоставляют ключевые показатели эффективности (KPI), которые описывают работу каждого из элементов системы. Нет ничего плохого в наличии KPI самих по себе, но в процессе поиска проблемы нужно проанализировать и сопоставить великое множество различных KPI. И насколько это будет эффективно?
Примем во внимание:
- Объем. Некоторые инструменты для мониторинга предоставляют сотни, тысячи KPI, позиционируя это, как свое преимущество - но переизбыток информации может сделать определение проблемы практически невозможным. Нам нужны не просто числа, нам нужен контекст! Знания только того, что конкретный ресурс загружен на ХХ%, недостаточно. Нужно понимать, как этот ресурс используется в нормальных условиях, чтобы можно было определить степень отклонения текущих значений от нормы.
- Полнота информации. Объемы данных постоянно растут, и многим другим системам трудно поспевать за этим ростом. Не получится проанализировать или визуализировать данные, которые они не собирают.
Очевидно, нет никакого преимущества от наличия KPI с огромным количеством сырых данных в том виде, в котором они базово поступают к нам. Поэтому, для преобразования информации в краткую и понятную инструкцию, необходима автоматизированная интеллектуальная система, которая позволила бы получить конкретную информацию о проблеме, а не просто разрозненные данные, на анализ которых придется потратить массу времени.
На примере одного из лидеров в отрасли сетевого мониторинга VIAVI Solutions и их платформы Observer рассмотрим, как сочетание подробных данных с автоматическим анализом и оптимизированным рабочим алгоритмом позволит нам гораздо более эффективно выявлять и решать проблемы производительности сетевых сервисов.
ШАГ 1: Автоматизируйте анализ данных
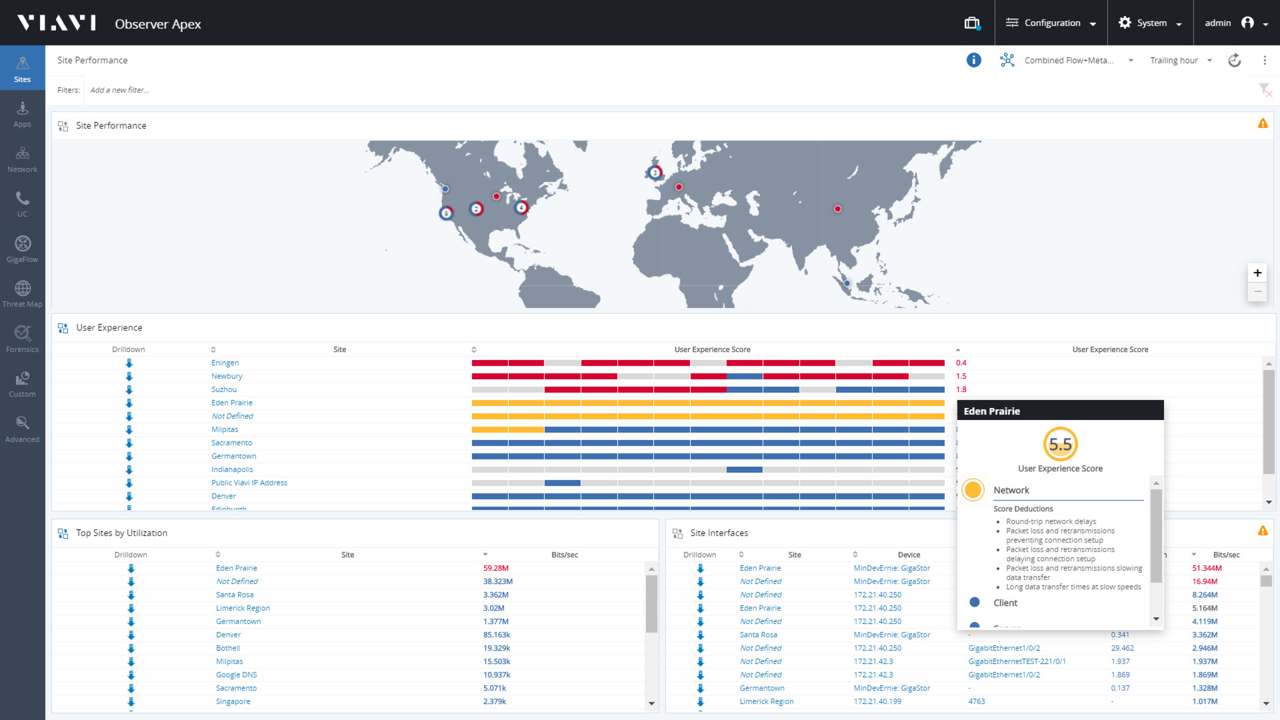
Скриншот дашборда "Site Performance" в платформе VIAVI Observer
Режим просмотра "Site Performance" позволяет увидеть работу каждой подсети – как сейчас, так и некоторое время назад. Здесь вы видите всего один ключевой индикатор - число (5.5), связанное с проблемной областью и описанием проблемы (сетевые задержки и повторные передачи). При этом вам не нужно думать о захвате каждого пакета, системном анализе каждого соединения, интеллектуальной консолидации и переводе десятков KPI в единую оценку – все это остается невидимым, оставляя только одно полезное значение, описание проблемы и указание на то, где она находится.
Давайте на секунду отвлечемся от этого.
Высокоуровневые режимы «Site Performance» и «Application Performance» показывают, как работают критически важные службы, а также качество с точки зрения пользователя или, по-другому, опыт конечного пользователя (EUE). Так что они, условно говоря, показывают, как работают сервисы.
Теперь применим эту информацию на практике.
ШАГ 2: Сфокусируйтесь на анализе трафика
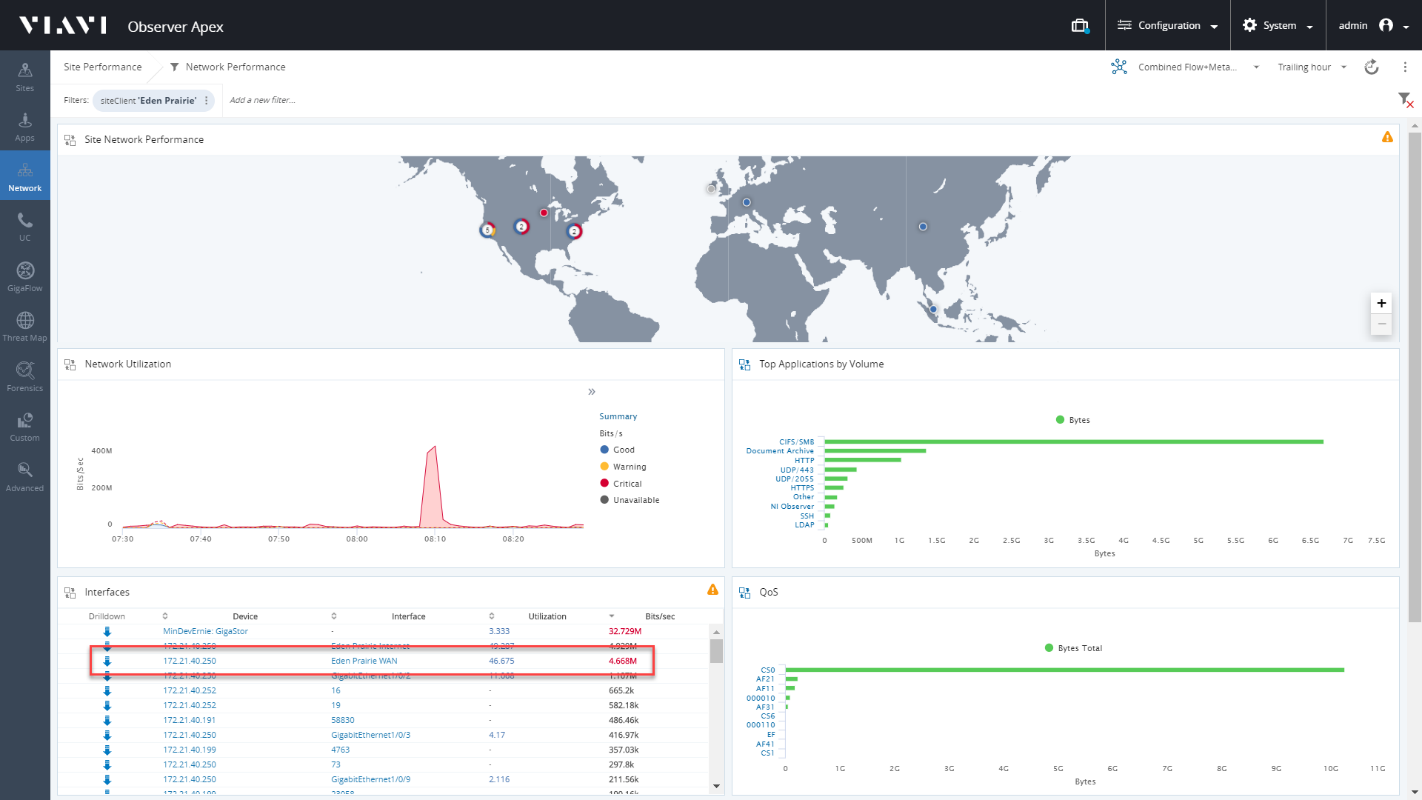
Скриншот раздела "Network" в платформе VIAVI Observer
Давайте переключимся на раздел сетевого мониторинга, где в одном месте сможем увидеть данные по производительности сети и её загруженности. Показатели автоматических параметров говорят о том, что интерфейс WAN демонстрирует необычно высокую загрузку.
В этом режиме мы можем увидеть распределение трафика и определить тот факт, что приложение «Document Archive» занимает неожиданно большую часть канала.
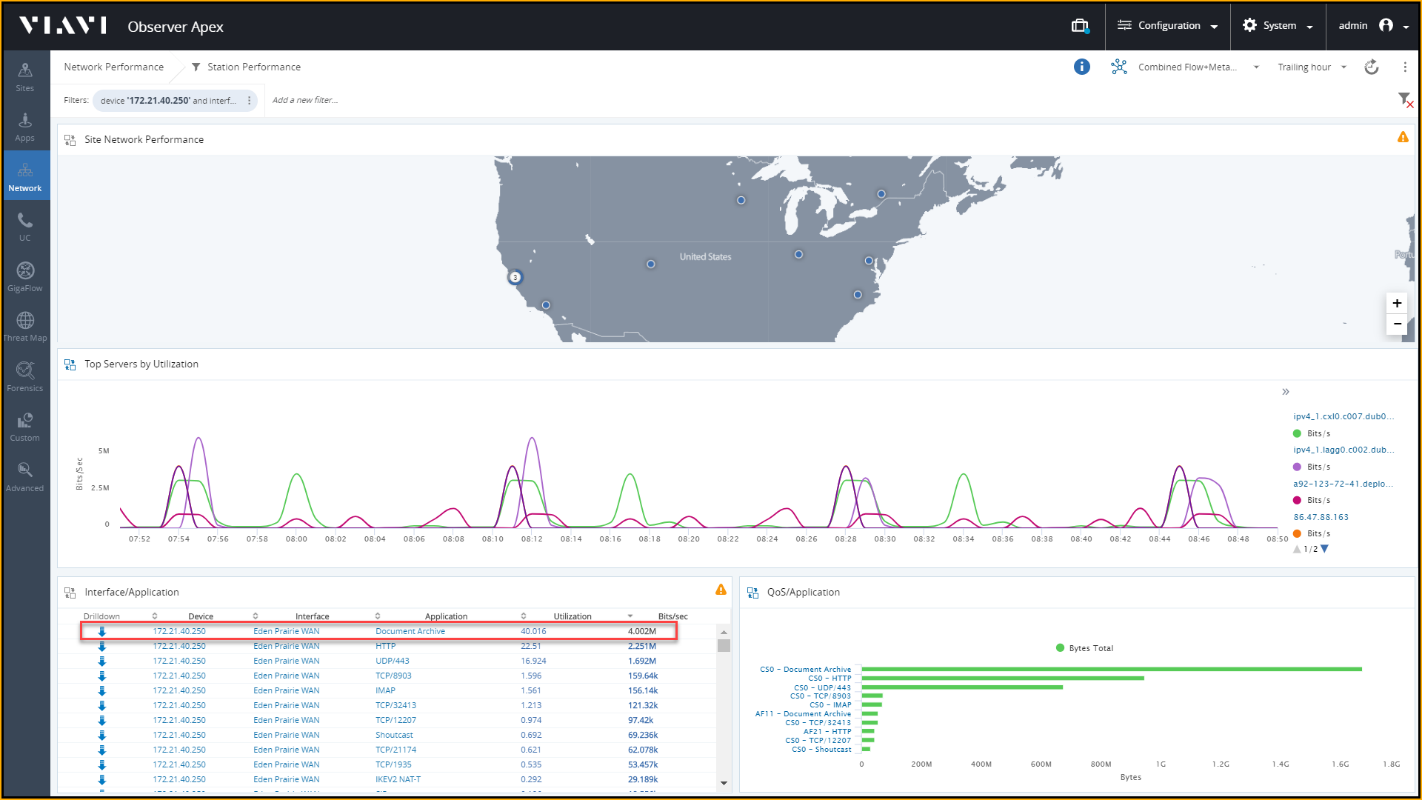
Скриншот раздела "Network" в платформе VIAVI Observer
Углубляясь в анализ трафика приложения, мы видим каждого клиента, использующего это приложение, а так же объем передаваемых им данных.
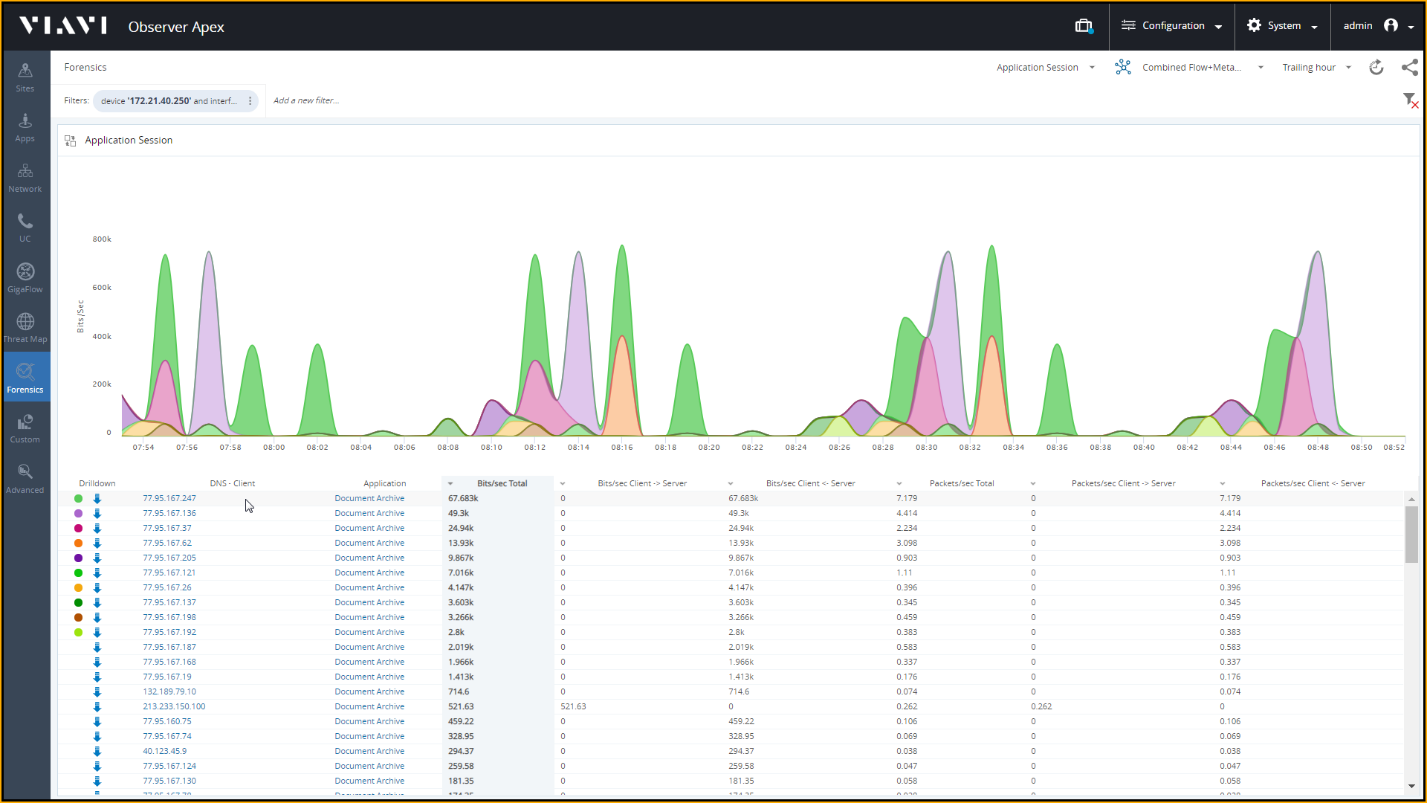
Скриншот раздела "Forensics" в платформе VIAVI Observer
Нужно больше подробностей?
Выберем одного пользователя и экспортируем пакеты, связанные с использованием «Document Archive» этим пользователем.
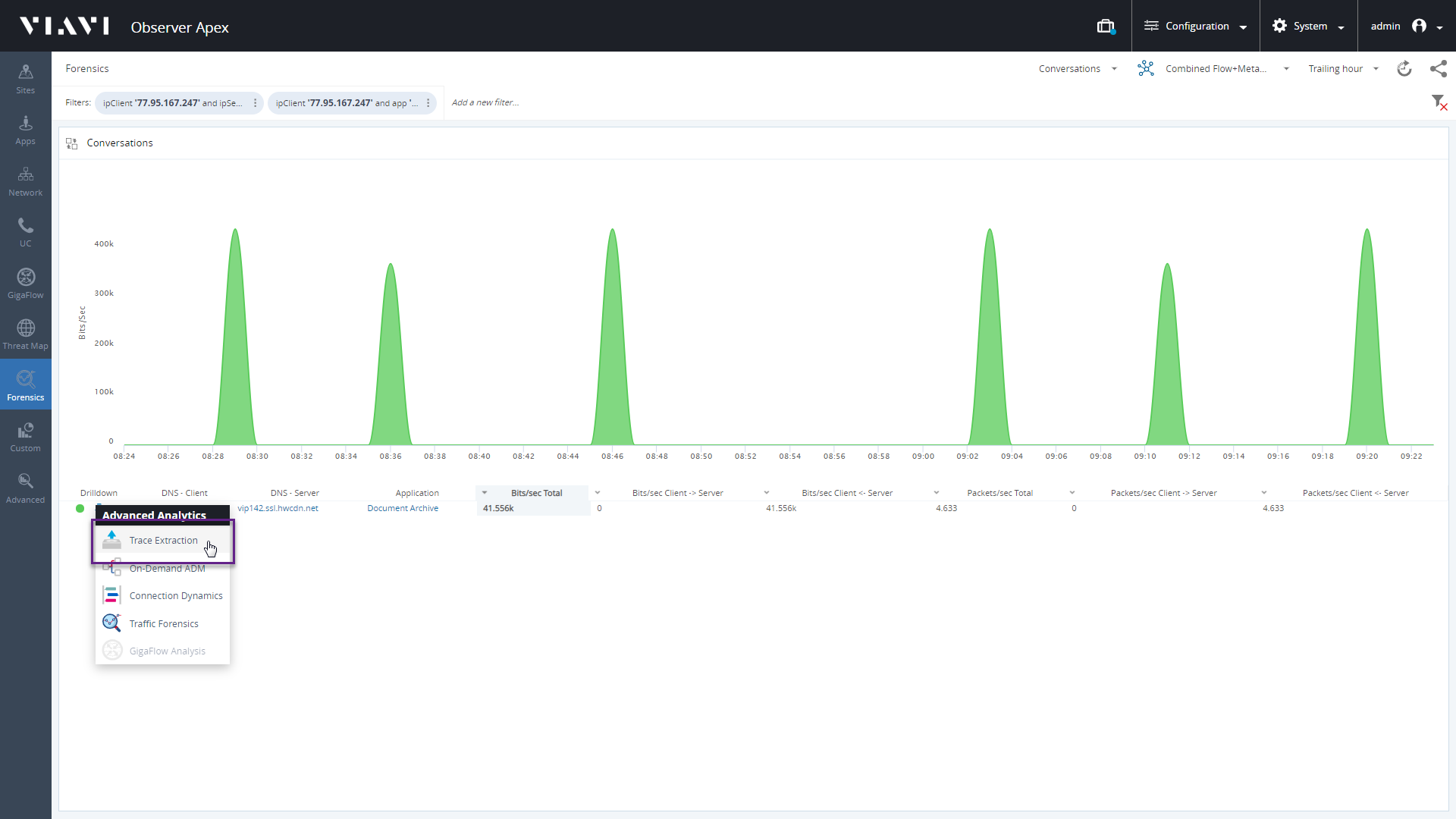
Скриншот раздела "Forensics" в платформе VIAVI Observer.
Что мы проиллюстрировали в этом примере?
- Преимущества использования автоматизированной системы для определения того, что возникла проблема производительности. Определение уровня этой проблемы и возможность ее масштабирования – «У нас есть конкретное место, в котором значения End User Experience Score в определенной степени ухудшается».
- Преобразование разрозненных KPI и необработанных данных в полезную информацию – это важная проблема сети.
- Ценность сочетания этой полезной информации с простым и эффективным рабочим алгоритмом. Благодаря этому мы перешли от выявления проблемы к подробному анализу за несколько щелчков мышью, руководствуясь только теми KPI, которые важны в данной ситуации.
- Простоту использования - практически любой член команды может увидеть и понять проблему и буквально переходить от карты подсетей к пакетам в случае необходимости. Служба поддержки может подтвердить эту проблему, создать задачу, назначить специалистов и выставить приоритет. Если технической поддержке третьего уровня будет необходимо принять участие, она получит четкое описание проблемы и только те исходные данные, что необходимы для ее решения.
- Ценность бесшовного объединения разрозненных данных. В этом примере наш рабочий алгоритм начался с EUE на основе пакетов, прошел через полностью интегрированные данные flow (NetFlow, IPFIX и т. д.) и закончился, снова вернувшись к пакетам. Для нас не было никакой необходимости выяснять, на какой именно источник данных нужно смотреть и как получить только релевантные пакеты и flow.
Вероятно, у вас уже есть все нужные данные. Однако пришло время увидеть, как заставить их работать на вас лучше всего.
В правильном рабочем алгоритме должно быть меньше работы и больше алгоритма.
Появились вопросы или нужна консультация? Обращайтесь!

Вечный параноик, Антон Кочуков.




Авторизуйтесь для этого