
.jpg)
.jpg)
Что такое Network Performance Monitoring (NPM)?
Без сети сложно представить работу любой компании и зависимость бизнеса от ИТ технологий продолжает неуклонно расти, поэтому мониторинг и оптимизация производительности сети (Network Performance Monitoring and Diagnostics) очень важная задача, которая стоит перед ИТ отделом. Если ранее компании контролировали состояние сетевых устройств и ключевых интерфейсов с помощью SNMP и RMON протоколов, то сегодня важно понимать работу ИТ-инфраструктуры в комплексе и как отдельные элементы влияют на производительность в локальной сети. В настоящее время все больше запросов со стороны корпоративных клиентов я получаю по контролю за работой арендуемых каналов у разных операторов связи и выполнением операторами соглашений о качестве сервиса (Service Level Agreements).
Мониторинг производительности сети (Network Performance Monitoring) - это программные и/или аппаратные компоненты, подключаемые к сети для контроля за производительностью сетевых компонентов, каналов связи и передаваемым трафиком.
Решения NPM в базовом исполнении объединяют функции сбора и хранения пакетов, передаваемых по сети, путем копирования реального трафика в систему анализа по основным бизнес приложениям и сервисам. Какие приложения контролировать решает каждый заказчик для себя сам и выбор осуществляется по сочетанию типа транспортного протокола и номера порта или диапазона портов приложения. Системы данного класса отличаются от классических решения Network Monitoring (Ping, SNMP pooling, Syslog и т.д.) тем, что работают c реальным сетевым трафиком. Информацию можно анализировать в реальном времени с точностью до секунд или анализировать агрегированную статистику за любой период времени вплоть до года.
Решения NPM отвечают на вопрос: «Как сеть доставляет пакеты?», и предоставляют следующие возможности:
-
Контроль состояния и доступности устройств.
-
Корректность настройки сетевого оборудования.
-
Мониторинг использования каналов связи.
-
Анализ поведения и работы приложений, пользователей.
-
Возможность захвата реального сетевого трафика.
-
Оценка качества голосового и видео трафика.
-
Автоматические уведомления о событиях и превышениях базовых параметров сети.
-
Построение отчетов в ручном или автоматическом режиме.
-
Корреляция событий в момент снижения производительности.
Контроль доступности и состояния устройств выполняется с помощью команды Ping по IP адресу устройства и/или порту приложения и с помощью запросов к MIB базам сетевого оборудования. Результатом выполнения данных запросов является статистика в виде наглядных таблиц или графиков с соответствующей цветовой кодировкой – зеленый (все хорошо), желтый (следует обратить внимание) и красный (есть реальная проблема). Система обращается к стандартным или настроенным идентификаторам объектов в MIB базе для получения требуемой информации. Также она может сортировать данные по географии, локальному или удаленному офису, типу сервиса или приложению. Наиболее удобные NPM системы хранят информацию в многомерных базах данных, что позволяет удобно делать подробную детализацию или настраивать фильтры под решаемую задачу. Например, тип сервиса, офисы, каналы связи, самые медленные приложения и т.д.
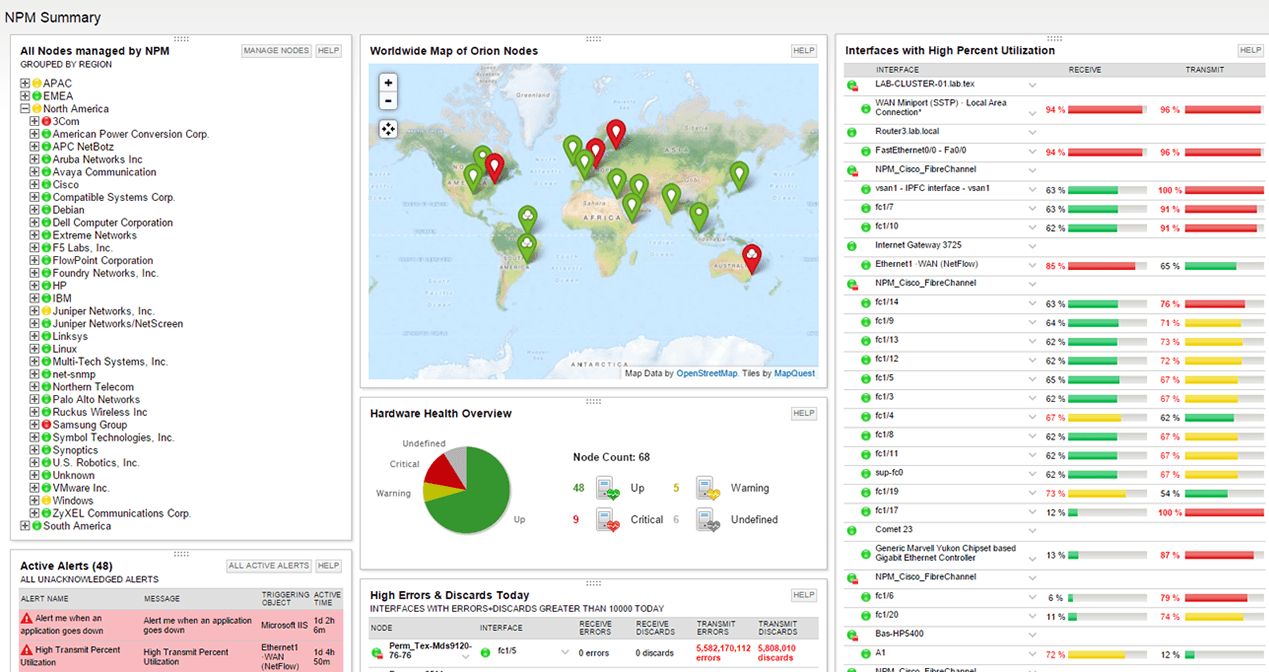
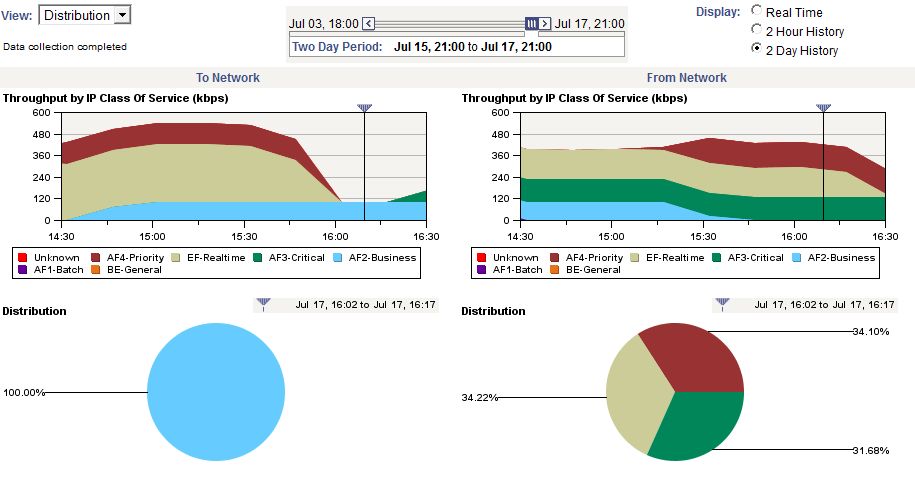
Корректность настроек сетевого оборудования с точки зрения передачи данных осуществляется на основе анализа заголовков пакетов и предоставления статистики по типам приложений и классов сервиса (CoS), с которым они передаются и борются за пропускную способность канала. На рисунке 2 мы видим полосу пропускания канала связи в направлении из локальной сети в сторону удаленного офиса и обратно с цветовой кодировкой передаваемого трафика в соответствии с принятым классом сервиса. На примере этого рисунка видно, что трафик из сети клиента передается с классом сервиса AF2-Business, а из сети приходят пакеты с классами AF3-Critical, EF-Realtime и AF4-Priority, а также наглядно предоставлена информация какую полосу пропускания занимает трафик с тем или иным классом сервиса.
Если система NPM и активное оборудование в сети поддерживает Flow технологии (NetFlow, IPFIX, sFlow, jFlow и т.д.), то мы можем контролировать использование каналов связи, проводить анализ поведения приложений и пользователей самым простым способом. Flow технологии уже заложены в купленное активное оборудование, а система NPM может принять их как Flow коллектор и предоставить необходимую статистику.
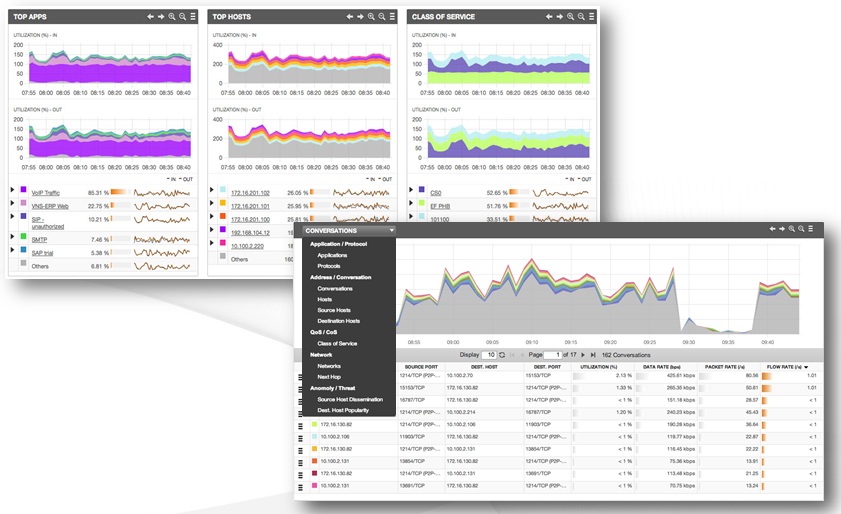
Flow технологии существенно не нагружают каналы и позволяют в единой точке иметь подробную информацию по использованию каналов всей территориально распределенной сети и ответить на такие вопросы как:
-
Какие пользователи работают в сети и какова продолжительность их сеансов связи?
-
Какие программы и приложения они используют?
-
Кто и какие приложения больше всего используют каналы связи?
-
Правильно ли настроена моя сеть с точки зрения классов сервисов?
-
Следуют ли пользователи политике использования сети?
-
Есть ли вирусы в моей сети, где они, как они туда попали, куда они распространяются?
Для передачи голоса по IP используется транспортный протокол UDP, который не имеет механизма установки гарантированного соединения и подтверждения полученных пакетов. Это означает, что при работе данной технологии возможны потери пакетов, задержки в каналах связи, а в совокупности с перегруженными каналами связи будет однозначно приводить к снижению качества голоса или обрыву вызовов. Улучшение качества VoIP решается путем присвоения данному сервису наилучшего класса сервиса, т.е. самого высокого приоритета, но это ведет к симметричному снижению производительности других бизнес приложений и сервисов. Следовательно, система оценки производительности сети должна иметь возможность оценивать это влияние путем анализа статистики по загрузке интерфейсов, анализу CoS по всей корпоративной сети и на стыках с арендуемыми каналами связи, а также вести анализ статистики по качеству речи в идеале с возможностью воспроизведения звонков
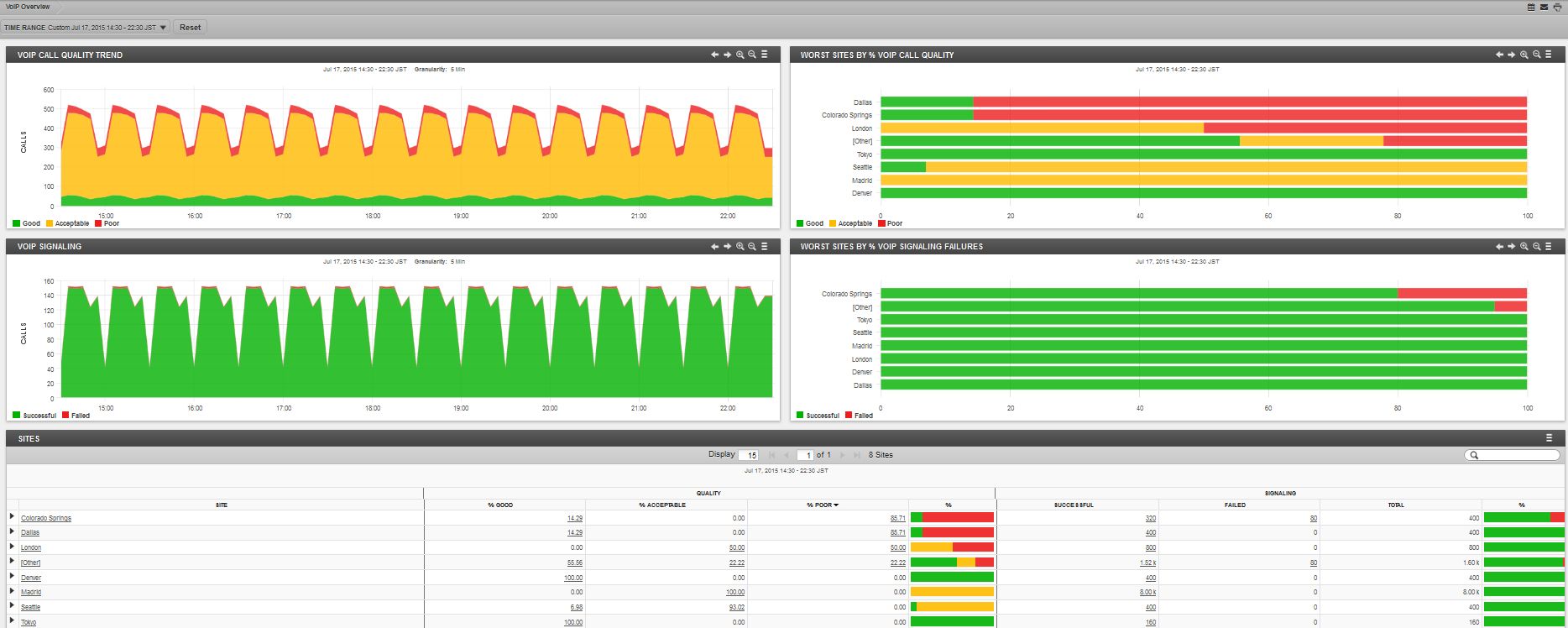
С чем приходится сталкиваться сейчас при общении с уважаемыми клиентами?
Установлено большое количество разрозненных систем контроля за работой сетевых устройств (Network Monitoring) без привязки к ключевым сервисам и приложениям. Кроме этого наблюдается отсутствие какой-либо корреляции событий, которые ведут к медленной работы сервисов. Истинная система мониторинга производительности сети должна быстро предоставить ответ из-за чего тормозит сервис – сеть, приложение, сервер и при отсутствии ИТ-специалистов на месте в автоматическом режиме выдать уведомление, опросить сбойные элементы сети по SNMP и захватить трафик, если это необходимо.
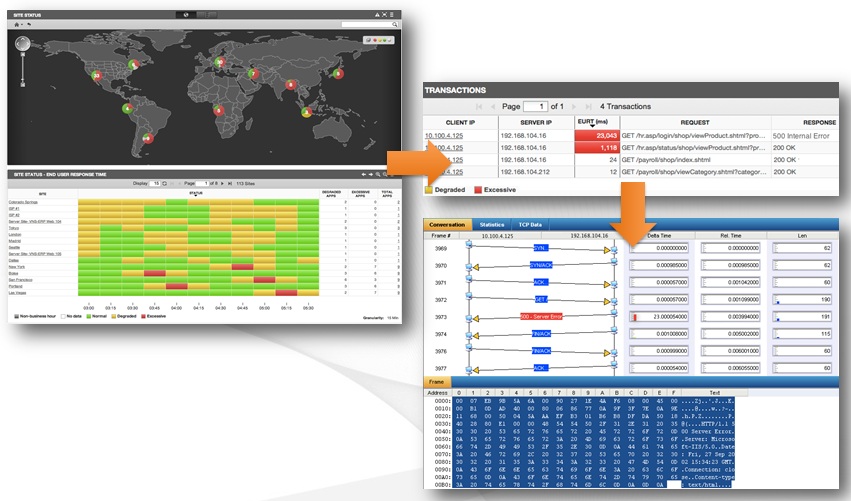
Таким образом, когда специалисты преступят к решению кейса, у них будет вся достоверная информация, что происходило в сети, когда пользователи начали жаловаться на медленную работу сервиса.
Идеальная система мониторинга за производительность сети должна:
-
Быть масштабируемая для покрытия всей сети и любых каналов связи для предоставления возможности мониторинга по принципу end-to-end, то есть от любого пользователя до любого сервиса или приложения
-
Быть всеобъемлющей и иметь возможность наращивания своего функционала с помощью лицензий или дополнительных программных или аппаратных агентов.
-
Обеспечивать контроль всех уровней сетевой модели OSI и возможность увеличения детализации вплоть до автоматического захвата трафика, который приводит к превышению установленных пороговых значений.
В рамках данной статьи я описал наиболее часто встречающиеся требования со стороны заказчиков к системам данного класса. Выбор системы мониторинга производительности сети не тривиальная задача, и требует внимательного подхода. Настоятельно рекомендую проводить пилотные проекты, чтобы убедится, что система обеспечивает все заявленные функции и не полагаться на маркетинговые описания и красивые слова менеджеров по продажам.
Всегда на связи, Игорь Панов.

Делитесь нашими статьями в соцсетях и задавайте вопросы в комментариях!
См. также:
- Решения Network Performance Monitoring (NPM). Руководство покупателя!
- SaaS сервисы: плюсы и минусы
- Анализ производительности ИТ-инфраструктуры: сегменты рынка по Gartner и основные игроки на нем





Авторизуйтесь для этого